简单来说,编译器就是一种能够将源代码保语义地变换为目标代码的程序。编译器和你我所写过的其他程序没有任何本质上的区别,它也是用代码编写出来的,并且只要想的话,你也可以写。本文尝试用一种很少有人尝试过的手段,破除笼罩在编译器上那层神秘的玄学面纱,在十分钟内教会编译器中的基本概念。
阅读本文需要读者具有一定的 JavaScript 基础。
语言
本文以一种 Scheme 语言的子集作为研究对象。这种语言使用前缀表示法来书写表达式:
(+ 3 4) ; 表示 3 + 4
(- 5 2 1) ; 表示 5 - 2 - 1
(* (+ 3 4) (- 5 2 1)) ; 表示 (3 + 4) * (5 - 2 - 1)
本文的内容只会用到简单的数学表达式,所以看懂上面这些就足够了。
语法树
对人类而言,要将源代码保语义地变换为目标代码,要做的事情无非就是:
- 阅读并理解源代码的含义
- 根据对源代码的含义的理解,输出一份目标代码
编译器采取的步骤也相差无几。而语法树就是编译器在“阅读并理解”源代码含义时所生成的中间结构。例如,对于
(* (+ 3 4) (- 5 2 1))
这个表达式,编译器可能生成像这样的一棵语法树:
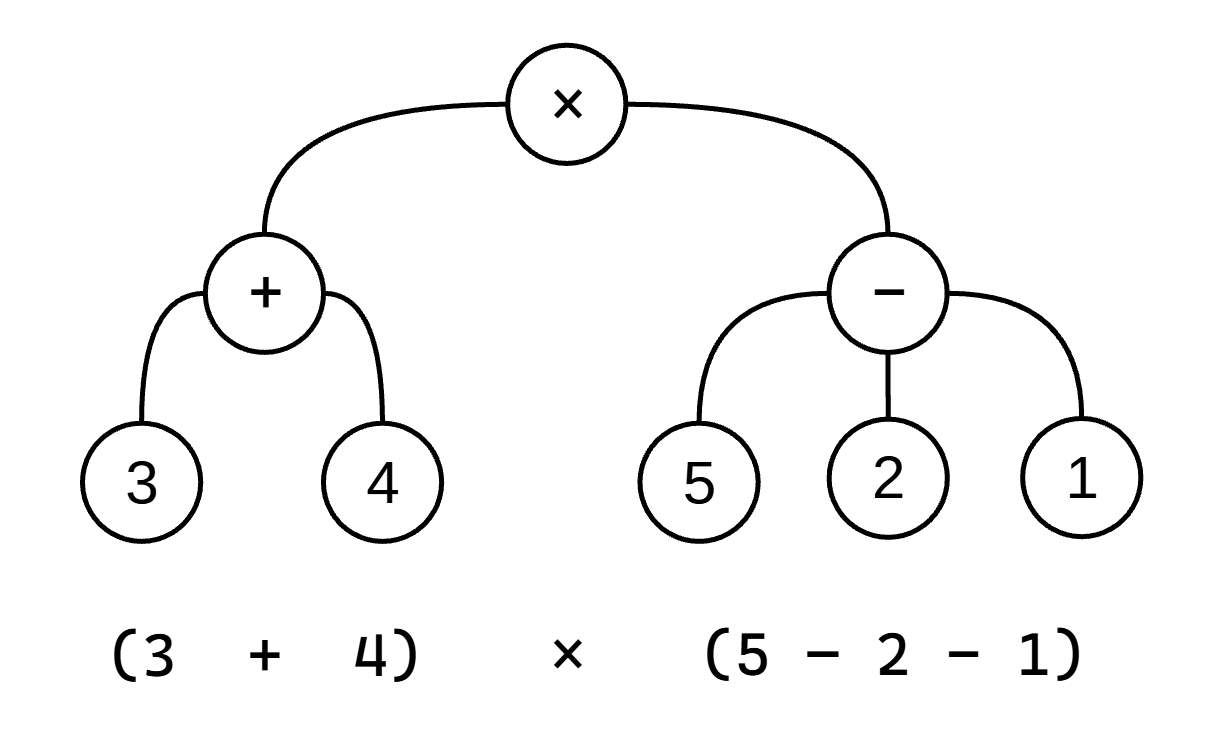
如果写成 JavaScript 对象,那么就会是:
{
operator: '*',
operands: [
{
operator: '+',
operands: [3, 4]
},
{
operator: '-',
operands: [5, 2, 1]
}
]
}
一般来说,语法树中会保存能记录源代码语义的所有信息,取决于语言的复杂程度,需要保存的信息有多有少。如你所见,与源代码相比,语法树是结构化的,非常适合交给自动化的算法处理。
⚠特别提醒:
有一些不负责任的教材特别喜欢教导学生如何在编译过程中省略语法树这种“中间结构”。诚然,省去这种中间结构可以让编译器运行的更快、消耗资源更少。但这么做对编译器和语言的潜能带来毁灭性的打击。事实上,在现代编译器中,省略语法树的操作极少出现。因此,尽管对于如此简单的表达式语言,省略语法树是可行的,但本文不这么做。
了解语法树这一结构之后,接下来要解决的问题就变成了
- 从源代码生成语法树
- 从语法树生成目标代码
从语法树生成目标代码
从语法树生成目标代码的过程相对来说直观且简单,所以本文先讲解这一部分。当拿到上面这样的语法树之后,基本上只要递归遍历它一遍,就能实现代码生成。比如从语法树生成常规的中缀表达式:
function generate(tree_item) {
if (typeof tree_item == 'number') {
return tree_item.toString()
} else if (typeof tree_item == 'object') {
var operands = []
for (var i = 0; i < tree_item.operands.length; i++) {
operands.push(generate(tree_item.operands[i]))
}
var ret = '('
for (var i = 0; i < operands.length; i++) {
ret += operands[i]
if (i < operands.length - 1) {
ret += ' ' + tree_item.operator + ' '
}
}
ret += ')'
return ret
} else {
throw new Error('malformed syntax tree')
}
}
var generated = generate({
operator: '*',
operands: [
{
operator: '+',
operands: [3, 4]
},
{
operator: '-',
operands: [5, 2, 1]
}
]
})
console.log(generated)
console.log(eval(generated)) // very sorry!
或者,如果想直接对语法树解释求值也可以:
function choose_reducer(operator) {
switch (operator) {
case '+': return function (a, b) { return a + b }
case '-': return function (a, b) { return a - b }
case '*': return function (a, b) { return a * b }
case '/': return function (a, b) { return a / b }
}
}
function evaluate(tree_item) {
if (typeof tree_item == 'number') {
return tree_item
} else if (typeof tree_item == 'object') {
var operands = []
for (var i = 0; i < tree_item.operands.length; i++) {
operands.push(evaluate(tree_item.operands[i]))
}
var reducer = choose_reducer(tree_item.operator)
var value = operands[0]
for (var i = 1; i < operands.length; i++) {
value = reducer(value, operands[i])
}
return value
} else {
throw new Error('malformed syntax tree')
}
}
console.log(evaluate({
operator: '*',
operands: [
{
operator: '+',
operands: [3, 4]
},
{
operator: '-',
operands: [5, 2, 1]
}
]
}))
从源代码生成语法树
按照“国际惯例”,从源代码生成语法树一般会有词法分析、语法分析和语义分析几个步骤。因为本文中使用的表达式语言目前为止还非常简单,不会引入什么语义问题,因此本文只会涉及词法分析和语法分析两个阶段。
词法分析
词法分析就是将整串的源代码,例如:
(* (+ 3 4) ; 分号后面是注释啦
(- 5 2 1)) ; 这里故意换了一行
去掉空白和注释,并切割成易于处理的词法记号:
['(', '*', '(', '+', 3, 4, ')', '(', '-', 5, 2, 1, ')', ')']
这一步操作有助于减少输入的复杂度,减少后续分析的工作量。词法分析总体上是非常 trivial 的工作,随手就能写一个:
function is_symbol(char) {
return char == '('
|| char == ')'
|| char == '+'
|| char == '-'
|| char == '*'
|| char == '/'
}
function is_number(char) {
return char == '0'
|| char == '1'
|| char == '2'
|| char == '3'
|| char == '4'
|| char == '5'
|| char == '6'
|| char == '7'
|| char == '8'
|| char == '9'
}
function lex_analysis(input) {
var result = []
var idx = 0
while (idx < input.length) {
if (is_whitespace(input.charAt(idx))) {
idx += 1
} else if (input.charAt(idx) == ';') {
while (idx < input.length && input.charAt(idx) != '\n') {
idx += 1
}
} else if (is_symbol(input.charAt(idx))) {
result.push(input.charAt(idx))
idx += 1
} else if (is_number(input.charAt(idx))) {
var num = ''
while (idx < input.length && is_number(input.charAt(idx))) {
num = num + input.charAt(idx)
idx += 1
}
result.push(parseInt(num))
} else {
throw new Error('unexpected character')
}
}
return result
}
console.log(lex_analysis(
'(* (+ 3 4) ; 分号后面是注释啦\n' +
' (- 5 2 1)) ; 这里故意换了一行'
))
语法分析
要构造语法树,就要先对语法有一个定义。本文所用表达式语言的语法可以简单地归纳为:
- 一个表达式就是一个程序
- 一个表达式
- 要么是单个数字
- 要么是由一个操作符和多个表达式作为操作数组成的复合表达式,用括号括起来
那么,在考虑计算机如何构造语法树之前,不妨先回想我们作为人类是如何分析上面那个表达式的:
- 从左到右开始阅读
- 遇到
(,表明这是一个表达式,接下来应该会跟着一个操作符和一串操作数。这个表达式的末尾应该会有一个右括号 - 遇到
*,这是期望中的操作符,接下来应该是一串操作数 - 遇到
(,表明这个操作数也是一个表达式,接下来应该会跟着一个操作符和一串操作数。这个表达式的末尾应该会有一个右括号 - 遇到
+,这是期望中的操作符,接下来应该是一串操作数 - 遇到
3,这是一个数字,作为操作数处理 - 遇到
4,这是一个数字,作为操作数处理 - 遇到
),表明从步骤 4 开始的那个表达式结束了,把这一整个表达式作为从步骤 1 开始的那个大表达式的操作数处理 - …
归纳起来就是:
- 从左到右阅读代码
- 根据当前读取到的词法记号,判断接下来要使用的规则
- 在遇到有嵌套的结构时,递归地运用的语法规则
这样,我们就得到了一种最简单且最直观的构造编译器语法分析器的方式:递归下降。手写一个递归下降分析器同样也很 trivial,如果看一遍读不懂的话就多看,思路跟着控制流走一走,或者干脆试试多抄几遍吧 =)
function parse_expr(context, tokens) {
var token = tokens[context.idx]
if (typeof token == 'number') {
context.idx += 1
return token
} else if (token == '(') {
context.idx += 1
return parse_compound_expr(context, tokens)
} else {
throw new Error('unexpected token')
}
}
function parse_compound_expr(context, tokens) {
var operator = tokens[context.idx]
if (!is_operator(operator)) {
throw new Error('unexpected token')
}
var operands = []
context.idx += 1
while (context.idx < tokens.length && tokens[context.idx] != ')') {
var operand = parse_expr(context, tokens)
operands.push(operand)
}
if (context.idx == tokens.length) {
throw new Error('unexpected end of input')
} else {
context.idx += 1
return {
operator: operator,
operands: operands
}
}
}
console.log(JSON.stringify(parse_expr({ idx: 0 }, lex_analysis(
'(* (+ 3 4) ; 分号后面是注释啦\n' +
' (- 5 2 1)) ; 这里故意换了一行'
)), null, 3))
⚠特别提醒:
有一些不负责任的教材特别喜欢贬低递归下降,认为它“不够通用”或是“不够强大”,并且浪费大量笔墨讲解非常复杂的、通过语法描述来“自动生成”语法分析器的“通用”方法。一定程度上来说,递归下降的问题是客观存在的,但并非无解。手写语法分析器的重复劳动确实比较枯燥,但自动生成也并非万灵药,且即便是在现在 (2023 年),相当多的编译器也仍在采用手写语法分析器以求实现更精确的控制。况且再怎么说,用笨拙点的方法也总比一上来就被复杂理论劝退要好得多。
结语
把上面那堆东西组装起来,你就获得了一个最基本的编译器(或者解释器)。你可以在 这里 找到完整的代码 (网页演示版本)。
这个 是原先使用现代一些的 JavaScript 编写的版本。
千里冰封曾经说过,“编译器入门是一个非常主观的东西,你觉得自己会了就是会了”。受篇幅所限,本文显然无法包揽编译技术的方方面面,但它应该能够给你提供足够帮你入门的知识,并且给予你进一步学习编译技术的自信。
此外,如果你读到这里还没发现整篇教程的代码都是用三空格缩进的,那就成为一个三空格奇数小王子吧!2 太少,4 太多,所以 3 刚刚好!
练习
- 扩展词法分析器的能力,让它支持小数点
- 扩展语法分析器的能力,让它能解析由多个表达式组成的程序
- *扩展整个“编译器”的能力,让它支持字符串类型的字面量,并规定字符串只能和字符串相加
- *在 3 的基础上,增加两个操作符
num->str和str->num,实现数字和字符串之间的转换
带星号的项目为进阶内容,不会做也没关系